Introduction
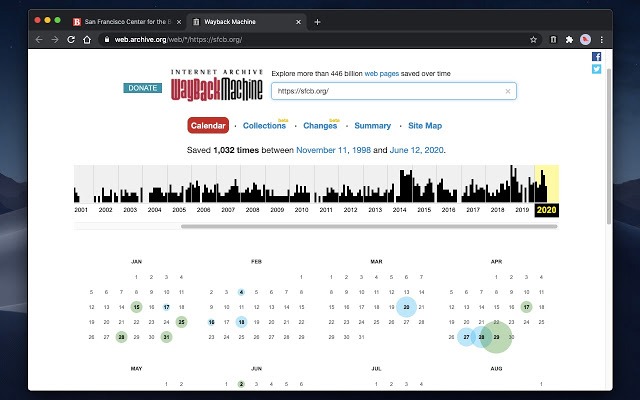
The Wayback Machine, operated by the nonprofit Internet Archive and available at archive.org, offers the ability to retrieve historical website content. The Wayback Machine was launched in 2001 with 10 billion archived pages, following an earlier 5‐year preliminary data collection effort. By December 2014, the Wayback Machine reported that it had archived 435 billion web pages worldwide. The earliest pages date back to 1996, with expansion in the scale and scope of its collections since the late 1990s through to the present with the global growth of websites and posts.1
For social scientists, the Wayback Machine offers a valuable large‐scale data source to analyze web information over time. There are many reasons why social scientists would wish to retrieve legacy web content: in our case, we are interested to explore how this web archive can be used in studying firm behavior, for example, to assess whether information about earlier firm strategies and practices can be associated with sales or job growth. Historical and current website information can serve as a complement to other sources of data. Some archived web information may substitute for items in a questionnaire: It is widely known that although questionnaires are a long‐established means to gather information about current characteristics and behaviors of companies, response rates to survey requests are dwindling (Baruch, 1999). Archived websites also provide a complement to other commonly used unobtrusive data sources—for example, corporate databases, scientific publications, and patents—which contain historic data but are often limited with respect to what the data set covers, be it financial information in the case of corporate databases, or limited information about scholarly research in publications and applications in patents. Moreover, in some fields, such as our current research into U.S.‐based small‐ and medium‐sized enterprises (SMEs) in the green goods industry, only 20% have a publication or patent, with the vast majority having their know‐how and trade secrets engineered into the product (Arora, Youtie, Shapira, & Li, 2014; Li, Arora, Youtie, & Shapira, 2014). Archived websites thus offer both a breadth of information about company practices and have the capability to present this information from prior periods.
However, using the Wayback Machine is not necessarily straightforward. Various methodological challenges are raised in accessing, analyzing and interpreting archived websites. These include standard social science issues such as field definition and bounding, sampling, and measurement, as well as specific challenges related to the Wayback Machine archive itself. This paper's contribution to the early but growing literature on the Wayback Machine concerns the approaches we used to identify and overcome these methodological issues. In particular, we put forth a six‐step process for accessing archived website information about SMEs, consisting of: (a) sampling, (b) organizing and defining the boundaries of the web crawl, (c) crawling, (d) website variable operationalization, (e) integration with other data sources, and (f) analysis. We conclude by pointing out the importance of automation and manual verification to maximize the value of the Wayback Machine for social science analysis.
The paper begins with a synoptic bibliometric review of the use of the Wayback Machine. This review is based on an analysis of publications indexed in Google Scholar that reference the Wayback Machine. These results show growing and broad‐based use of the Wayback Machine over the past decade in computer science, information retrieval, and library and archival fields, but rather less use in social science analysis. These approaches are addressed in the subsequent sections of the paper. We present a process for making use of Wayback Machine archived websites for social science analysis. This process is applied to a data set of U.S.‐based SMEs in green goods industries to exemplify its operation. The paper closes by acknowledging limitations in using archived websites along with a discussion of how we have addressed these limitations and what pathways for future research could be pursued to improve the use of archived websites.
The Webscraping Process
In this section, we describe our methodological approach to webscraping using the Wayback Machine. We illustrate this process using results from an analysis of U.S.‐based SMEs in green goods industries. Green goods industries include the manufacturing of (a) renewable energy systems; (b) environmental remediation, recycling, or treatment equipment; and (c) alternative fuel vehicles, energy conservation technologies, and other carbon‐reducing goods (for details about this definition, see Shapira et al., 2014). We abbreviate companies manufacturing in these industries as green goods companies (GGC). The objective in our use of archived GGC websites is to develop innovation activity indicators from historic company websites archived in the Wayback Machine to investigate the growth of GGCs. Our overarching goal in this paper is to provide an understanding of the steps involved with using the Wayback Machine in social science research based on our experience in this project. To this end, we walk through the six key steps: (a) sampling, (b) organizing and defining the boundaries of the web crawl, (c) crawling, (d) website variable operationalization, (e) integration with other data sources, and (f) analysis.
Step 1. Sampling
In the business sector, websites present a broad array of information about companies, products, and services, and thus offer promising opportunities for webscraping on a range of questions. Business website use has become widespread, although there are variations by types of firms. For example, in a companion analysis by Gök, Waterworth, and Shapira (2015) of GGCs in the United Kingdom, the authors observe that just under three‐quarters of U.K. companies with at least one employee report that they maintain a website. The percentage with a website rises to 85% for companies with 10 or more employees in all economic sectors in the United Kingdom and 91% for manufacturing companies with 10 or more employees. Yet, although larger firms typically maintain websites (some of which can be very extensive), many smaller firms also present a significant amount of information about their company in part because they use their website as a tool for selling services or attracting investment. In some cases, the amount of information on smaller firm websites is more extensive than one would see in websites of large corporations. Although it is true that there are smaller firms who may present less information, as well as some small firms not having their own online presence, the websites of those SMEs that are online can reveal indications of innovation activity. However, it should be noted that sometimes there are gaps in even these online firms' web presence. Arora, Youtie, Shapira, Gao, and Ma (2013) report that some high‐tech, small firm websites may “go dark” to protect their nascent and evolving intellectual property, especially when in preproduct stages. Their websites can remain online but with very limited content.
In order to use webscraping for data extraction, the analyst should first make sure the sample meets a few pre‐requirements for web data. These pre‐requirements include:
Do the organizations in the sample have websites?
Do their websites provide information to answer the analyst's research questions?
Does the Wayback Machine capture the relevant historical websites?
We use the GGC analysis as the main example to illustrate how to build these pre‐requirements into the sampling process. The research focus of the GGC analysis was on the innovation activities of U.S. GGCs and how these activities may or may not be associated with company growth. The basic requirement of our sampling approach was that these SMEs had websites. First, we found that the proportion of the population of GGCs with websites was relatively high, at least in the United States, particularly for those companies that have employees. In our GGC analysis, not all firms with current websites also had websites archived in the Wayback Machine, thus necessitating (at least) two rounds of formative sampling. In the first round, of the roughly 2,500 U.S.‐based SMEs manufacturing in green goods industries, approximately 700 had current websites. Of these 700, only 300 both did manufacturing in some green goods area and had current and at least one archived website (see Shapira et al. [2014] for how “green goods” was operationalized). We subsequently found that nine of these companies had gone out of business. This gave us 291 GGCs in our database, although subsequent efforts to integrate with other data sources (specifically Dun & Bradstreet's Million Dollar database which provided us with sales and employment growth figures), led us to discard 19 additional GGCs that had missing data points in the Dun & Bradstreet database.
Second, we found that current and archived websites of these SMEs had a diversity of information about company innovation activities and business approaches. Information about products, technologies, company news, and other business‐related communications was much more readily available at the level of the SME than in large corporate websites, the latter of which tend to focus on financial reporting, corporate responsibility reporting, and broad market segments. In our GGC analysis, we found that nearly all the U.S. GGCs in our sample had a detailed product page or set of pages and two‐thirds had information about their research and development activities (Arora et al., 2014).
A third requirement concerns whether the Wayback Machine captured historical company website information. The Wayback Machine crawls websites in recurring yet not necessarily predictable, periodic intervals. For example, although some sites are crawled every month or so, others may only be revisited once a year or every other year. The Wayback Machine archives only publicly accessible pages, and pages protected by passwords or “do not crawl” exclusions (e.g., robots.txt files that disallow access) are not archived, nor are pages with embedded dynamic content (e.g., as enabled by JavaScript). In addition, pages not linked to another page (i.e., orphaned pages) also are not likely to be archived in the Wayback Machine.2
The Wayback Machine says that it can take 6 or more months (and sometimes longer, up to 24 months) for archived pages to appear.3 We found variations in the frequency of Wayback visiting any particular page, as well as the depth of the crawl given a “seed” page. In our GGC analysis, for example, one GGC had 34 pages in 2008, two pages in 2009, and six pages in 2010. Our experience suggests that some pages (e.g., home pages or whole websites associated with highly visible organizations) may be crawled more often than other pages, and there is no readily available explanation describing the variance in capture‐rates between one page (or site) and another. Therefore, although in general the Wayback Machine offers a way to generate panel data sets by year with a site or corresponding firm as the unit of analysis, missing data are a significant challenge as firm data vary from year to year. We worked around this limitation by combining observations to produce longitudinal data pooled across multiple years. One of the studies coming out of our GGC analysis used this technique. Li, Arora, Youtie, and Shapira (2014) collected 4 years of website data (2008–2011) from the Wayback Machine for the 300 GGCs. But in order to construct a balanced data set, the researchers had to use two aggregate time period, 2008–09 and 2010–11, instead of each year.
Step 2. Organizing and Identifying the Boundaries of Web Crawl
Webscraping begins with identifying the boundaries of a collection of webpages, either current or archived, which is going to be searched and downloaded (“web crawling”) later. Although this article focuses on archived websites in the Wayback Machine, the step is also applicable to current webpages. This step needs to address two issues:
What kind of information presented on webpages need to be crawled?
Which webpages on an organization's website should be included in the collection?
The immediate issue is determining what kind of information on the webpages can be captured. The casual user may personally view a website and look for common cues, such as design elements, text and graphics, menus (navigation), or “about us” pages. Yet capturing this information in web crawling is much more complicated. First, there is a great deal of variance in the way websites are designed and specified. For example, to what extent is Flash (a graphics and animation software platform) present, either in the whole site or just the menus, multiple languages, and subdomains? Most webcrawling software cannot extract dynamic content in Flash platforms; thus, only limited data are able to be extracted from Flash‐based websites by crawlers because the content is not in HTML (or variants thereof), rendering extracted data from these websites as incomplete representations of the original. Flash‐based links between pages are also a problem in this regard, making links between pages not readily traversable. Second, the analyst has to rely on computer software to process the searching and downloading of a large number of webpages. While the capabilities of computer software have been growing with the adoption of increasingly powerful processors, there are still serious limitations on how many pages can be crawled. Third, although HTML pages in multiple languages are not usually a technical problem, some crawlers cannot handle a multitude of text encoding types (e.g., Unicode), so that multilanguage capability needs to be checked. In the GGC analysis, we employed IBM Content Analytics for web crawling (along with some custom Java code). IBM Content Analytics is a Linux‐based software package with the capabilities to process HTML webpages as well as Adobe Portable Document Format (PDF) and Microsoft Word documents. The capabilities of other crawler software may vary.
The next step is to define the scope of a target website's webpages to be crawled. Our general approach was to use a set of seed Uniform Resource Locators (URLs), that is, web addresses, and a number of corresponding domains to indicate which links will be traversed and which links are out of scope. The domains essentially act as boundary constraints in the crawl.
By way of explaining our approach to organizing and identifying the boundary conditions, we began by assuming D domains and S seeds, where D ≈ S. The process for defining S and D is uncomplicated for “current” websites. For instance, to crawl “example123.com” as it currently appears on the World Wide Web (WWW), we set S = {http://example123.com} and D = {example123.com}.
Crawling the Wayback Machine complicates the process because the specification of S and D must include Wayback Machine URLs.4 To illustrate, we first identified N seeds; next we created a domain pattern that captures everything on that site in a given time period. For this example, we retrieved pages in 2004 using two auto‐generated seeds:
S = {https://web.archive.org/web/20040301000000/http://example123.com,
https://web.archive.org/web/20040901000000/http://example123.com}
and
D = {web.archive.org}.
In S, specifying two time‐stamped URLs (one in March and the other in September) increases the likelihood of the Wayback Machine landing on an archived page within the target year.5 We also identified seeds through manual inspection of the archived pages in the Wayback Machine for certain collections that were difficult to identify through autogenerated seeds.
When crawling the Wayback Machine, we specified an additional set of “allow” rules A that provided boundary conditions for the crawl within Wayback (Figure 2). In this case, A = {https://web.archive.org/web/2004*example123.com*}. The asterisks in A act as wildcard characters to retrieve URLs that match the specified pattern. However, to omit other pages that might also be crawled, we needed a further set of rules to prevent crawling of the rest of the Wayback Machine. This is the omitted rule set O, which is represented as {https://web.archive.org/*}. Under this specification, only pages containing the string “example123.com” from the Wayback collection in 2004 will be retrieved.