
Screaming Frog Group Buy Account - 1 year License Key
Screaming frog Pricing is £149.00 Per Year, you can get Screaming frog one year License Key for just $20 from GroupBuyExpert.com service.
Please see the full list of tools available here: https://groupbuyserver.com/
Screaming frog Pricing is £149.00 Per Year, you can get Screaming frog one year License Key for just $20 from GroupBuyExpert.com service.
Screaming Frog has been my first choice SEO tool for a while now. It has the power to uncover almost all potential issues with your site for improved analysis. It is important to improve website health by finding problems and fixing them before optimising other areas of your site. Let’s see how Screaming Frog helps you achieve that.
Main Benefits:
Screaming Frog makes it easy to find broken links (404s) and server errors on your site. Fixing these allows search engine spiders to seamlessly crawl your site and navigate every page. It’s also always beneficial to spot (and update on-site) temporary and permanent redirects, which can be done with Screaming Frog without any hassle.
Checking and analysing page title, meta tags and headings to resolve potential authority issues is no longer difficult either, and duplicate content is much easier to find with Screaming Frog’s data.
As an added plus, it also allows for XML Sitemap generation and integration with Google Analytics.
Try Screaming Frog with cheap price on Group Buy SEO Tools.
Versions:
A free version is available but it has limitation to crawl just 500 pages – this is sufficient for smaller sites. For larger sites, it is worth buying the full paid version especially when we see the benefits and ease of use when crawling much larger sites. A new version for Screaming Frog (9.0) has recently been released with several useful features that complement the ones we’ve already been utilising. The most useful new features include the following.
The ability to store the HTML source code with the crawl file that can be used to take websites’ HTML backups and for future reference.
In addition to that, further configuration options have been added to the XML sitemap export function. e.g. pages with ‘noindex’ tag or pages with server errors or redirection can easily be excluded from the resulted sitemap.
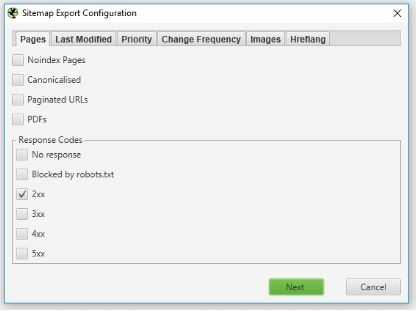
Moreover, a powerful search function has been introduced to quickly locate pages with the custom field search.
Now, let’s take a look at some useful configurations:
The newly added feature of storing HTML, that we just discussed above, can be found under Configuration > Spider > Advance Tab.
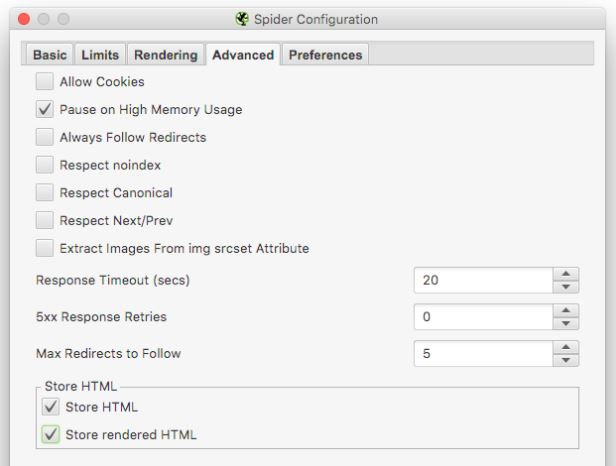
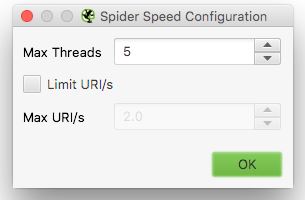
Another useful configuration is the speed, especially when your hosting server is lacking resources or there are heavy traffic or load on the website. It allows you to decrease the maximum number of threads when Screaming Frog crawls the website to adjust the load accordingly so that when it crawls, it doesn’t hit the website hard.
What if the web server is blocking Screaming Frog spider or the Googlebot to crawl the website? Or if there is a customised behaviour depending on the type of browsers, or if you have a separate mobile site? In this scenario, Configuration > User Agent is the section required.
Custom Search under Configuration helps to find up to 10 search phrases in the source code per crawl. It can be useful to find empty category pages from an e-commerce website or to find opportunities to improve internal linking for a specific key phrase.
Finally, there is an option to combine the power of Google Search Console, Google Analytics, Majestic, Ahrefs and Moz with Screaming Frog crawl, which is very useful to figure out the pages with less traffic or clicks, or the ones driving the most traffic to the website to further optimise them.

3 Ways You Should Be Using Screaming Frog
External Link Checking
For all the linkbuilders out there, one of the most upsetting things is discovering your hard earned links disappearing some time after you’ve curated them. You may well be keeping a spreadsheet with your link building efforts – run them through the tool using Configuration > Custom > Search tab. Here’s a step by step example to make it clearer:
Let’s say your client is the BBC. Go into Configuration > Custom > Search and put Does Not Contain www.bbc.co.uk
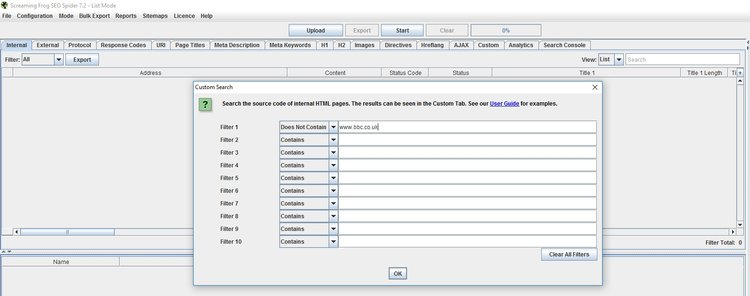
Switch over to Mode > List and upload your list of links. Upload them via file or paste at the top of the program. In this very crude example it’s essentially saying BBC had links in the past on Wikipedia and ITV.

Run the crawl and navigate in the internal tabs to Custom.
What you should see in here are links which do not contain “bbc.co.uk” within the pages listed above.
Here is what we find. No surprises that ITV are included in this tab i.e. they are not linking out to the BBC.

If you regularly incorporate this activity into your monthly work you can get in touch with webmasters when a link disappears – doing this in a timely fashion will mean they are more likely to reimburse your link.
Auditing
In 2017, consumers using mobile devices are ever increasing. Thus it’s imperative to audit for mobile first recommendations over desktop. In order to do so in Screaming Frog a few options are needed.
Under Configuration > Rendering change to JavaScript rendering, timeout should be set to 5 seconds (as from tests, this is what Google seem to be using for the document object model snapshot time for headless browser rendering) and window size to your device of choice (Google Mobile: Smartphone).
You’ll also want to change your HTTP Header to GoogleBot for Smartphones to mirror how Google will interpret your page.

Crawling like this obviously takes 5 seconds or longer per URL, so be wary of this and perhaps restrict to a select list of URLs. Once you crawl your page(s), in the bottom pane, change to the Rendered Page view tab. You will see a mobile shaped snapshot of how your pages is rendered and audit from there.
Custom Extraction
One of the newer features is the ability to scrape custom on-page content. This is great for scraping data such as product counts for E-commerce sites or social buttons from a blog. The list goes on. Essentially any on page element you can find the CSSPath, XPath or Regex for you can scrape.
The first thing you might want to do is decide what on page content you might be after. Right-click on the content you wish to scrape and Inspect Element. There is also a neat little tool in the top left of the interface which looks like a cursor which can aid you identifying your element of choice.
Once you’ve got your element of choice highlighted right click > copy > Xpath or Outer HTML.
Please note, some elements do require knowledge of Xpath to extract them properly. Take a look over here on w3schools’ tutorial to find out more.
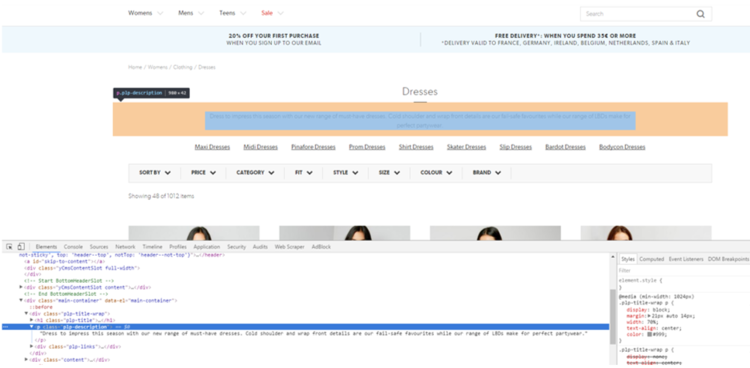
Once copied, paste your Xpath, CSSPath or regex into the extractor and select what part of that element you require.

This can be a bit of trial and error when you first begin so try a range of options and hopefully you’ll get what you want with a bit of tinkering around. If you are interested in scraping, Mike King’s guide to scraping every single page offers a comprehensive guide.
 Once you get the hang of using multiple custom extractors there is an option to save your current configuration. If you are regularly doing audits this can be useful!
Once you get the hang of using multiple custom extractors there is an option to save your current configuration. If you are regularly doing audits this can be useful!
Navigate to the right hand side of the Screaming Frog interface or the custom column to find your custom extracted data ready for use.
There’s heaps more you can do with the tool and loads of resources online. If you want to learn more a good place to start is the user guide and FAQs.
Screaming Frog SEO Spider Crawling Tips for Ecommerce Sites
1. Most of the Things you’re Struggling with can be Solved with a Ticky Box
I’ve used the SEO Spider tool for a good five or so years now, but there are still times when the tool doesn’t act how you want it to. That said, there’s a lot of things that can be solved by tweaking just a few settings, it’s just a matter of knowing where they are.
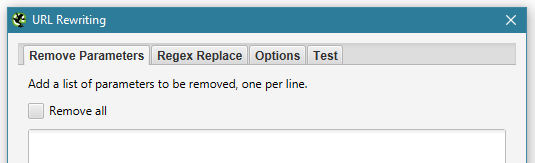
2. Eliminating all URL parameters in your crawl
This is an issue which some of you that have used the tool may be familiar with. Performing a crawl without removing your product parameters – shoe size, colour, brand etc – can result in a crawl with potentially millions of URLs. There’s a great article by Screaming Frog on how to crawl large sites which advises you to use the exclude function to strip out any URL parameter you don’t want to crawl (Configuration > Exclude). What I didn’t realise was, that if you just want to exclude all parameters, there’s a handy little ‘remove all’ checkbox that lets you do just that (Configuration > URL Rewriting).
3. Screaming Frog’s SEO Spider is an Amazing Scraping tool!
Custom extraction is something I’ve been playing around with for a while when crawling sites (Configuration > Custom > Extraction). For those who are unfamiliar; custom extraction basically allows you to scrape additional data from a URL when performing your crawls. Data such as:
- The author of a blog post
- How many comments a blog has received
- Social media share counts
- Email addresses mentioned on the page
- Structured data – such as the average star rating of all of your products
There are 100s of possibilities when it comes to custom extraction – I may even be inspired to write a blog on this alone (we’ll see how well this one goes down first). This data is so valuable for internal SEO audits and for competitor analysis. It gives you extra insight into your pages and lets you draw more accurate conclusions on why a page or a set of pages is outperforming others.
One of my favouirte things to do with custom extraction, is to pull out the number of products in a set of category pages. This data can help you determine which pages to remove or consolidate on your ecommerce site. For example, if you’ve got several category pages with less than five products in it say, and you’re competing with sites which contain 100’s of products, it’s highly unlikely you’re going to outrank them. In these cases, it could be best to canonicalise it into the parent category, noindex it or in some cases, just delete and redirect it if it receives little to no traffic.
Sometimes, however, I’d crawl a site and the custom extraction data was missing. I now realise this was down to the Javascript. By default, the SEO Spider will crawl in text only mode, i.e. the raw HTML from a site. However, some site functionality, such as the script which runs to tell us how many products there are on a page, is handled using JavaScript.

Putting the spider in JavaScript mode (Configuration > Spider > Rendering > JavaScript) and running the crawl on this set of URLs again unlocks this additional layer of data. Another headache solved by a simple drop-down menu.
4. Pull in Keyword and External Link Data into your Crawls.
Another really handy feature which I’ve experimented with, but not to its full potential, is the ability to tap into third-party APIs. As an SEO, there are a number of tools which I use on a daily basis: Google Analytics, Search Console, Ahrefs, Moz, this list goes on. The Spider Tool, lets you pull in data from all of these platforms, into one crawl. Data such as how many organic sessions your landing pages have generated, how many impressions a particular page has and how many external links point to your pages.
Knowing the data that’s available, and knowing what to do with it are two separate matters however, but through a number of exports and using the good old vlookup function, you can use this data to put together a handy content audit and prioritise areas of the site to work on. Let’s take the below as three very basic scenarios, all data which is available via the SEO Spider.
| URL (SF) | Organic Sessions (GA) | External Links (AH) | Internal Links (SF) | Impressions (SC) | Potential Solution |
| /product1 | 10 | 0 | 10 | 1000 | Low traffic but a decent number of page impressions. Few internal/external links – focus on building these |
| /product2 | 100 | 1 | 30 | 500 | Good organic traffic. Could be a result of the number of internal/external backlinks that point to this page. |
| /product3 | 50 | 1 | 0 | 300 | No inlinks may suggest an orphaned page/not in the sitemap. Potentially deleted product – redirect to an alternative |
Key: SF = Screaming Frog, GA = Google Analytics, AH = Ahrefs, SC = Search Console
Again, by having the data all in one place, you’re able to get a better insight into the performance of your site, and put together an action plan of what to prioritise. Combine this with custom extraction data such as product reviews, product descriptions and so on, and it really does become a powerful spreadsheet.
SEO Spider Training Conclusion
So there you go, just a handful of useful things that I got out of the training session. The aim of the course was to boost everyone’s confidence in being able to crawl a website, and I personally believe that was delivered. As the first ever group of trainees – aka the guinea pigs – the training was well structured with enough caffeine to stop everyone’s brains from shutting down.
My one negative is that there was perhaps too much information to take in. I mean, it’s not like me to complain about value for money, but there were times when we delved into data visualisation when I glazed over. On a personal front, I’ll be looking to brush up on my regex knowledge to help with the more advanced custom extractions. Or, alternatively, I’ll stick to bribing our devs with tea and cake. Hopefully, Screaming Frog put on more of these training days in the future, outside of London. I would highly recommend anybody who wants to expand their ability to crawl a site to attend.
How to Use Xpath for Custom Extraction in Screaming Frog
Basic Syntax for Xpath
You can scape almost anything in an XML or HTML document using xpath. First, you’ll need to know the basic syntax.
// – Selects the current node no matter where it is located in the document
//H2 – Returns all H2’s in a document
/ – Selects from the root node
//div/span – Only returns a span if contained in a div
. – Selects the current node
.. – Selects the parent of the current node
@ – Selects an attribute
//@href – Returns all links in a document
* – Wildcard, matches any element node
//*[@class=’intro’] – Finds any element with a class named “intro”
@* – Wildcard, matches any attribute node
//span[@*] – Finds any span tag with an attribute
[ ] – Used to find a specific node or a node that contains a specific value, known as a predicate
Common predicates used include:
//ul/li[1] – Finds the first item in an unordered list
//ul/li[last()] – Finds the last item in an undordered list
//ul[@class=’first-list’]/li – Only finds list items in an unordered list named “first-list”
//a[contains(., ‘Click Here’)]/@href – Finds links with the anchor text “Click Here”
| – AND, selects multiple paths
//meta[(@name|@content)] – Finds meta tags with both a ‘name’ and ‘content’ attribute
Xpath for Extracting Schema Code
Scraping structured data marked up with Schema code is actually pretty easy. If it is in the microdata format, you can use this simple formula: //span[@itemprop=’insert property name here‘] and then set Screaming Frog to extract the text. Keep in mind, however, that xpath is case sensitive so be sure to use the correct capitalization in the property names.
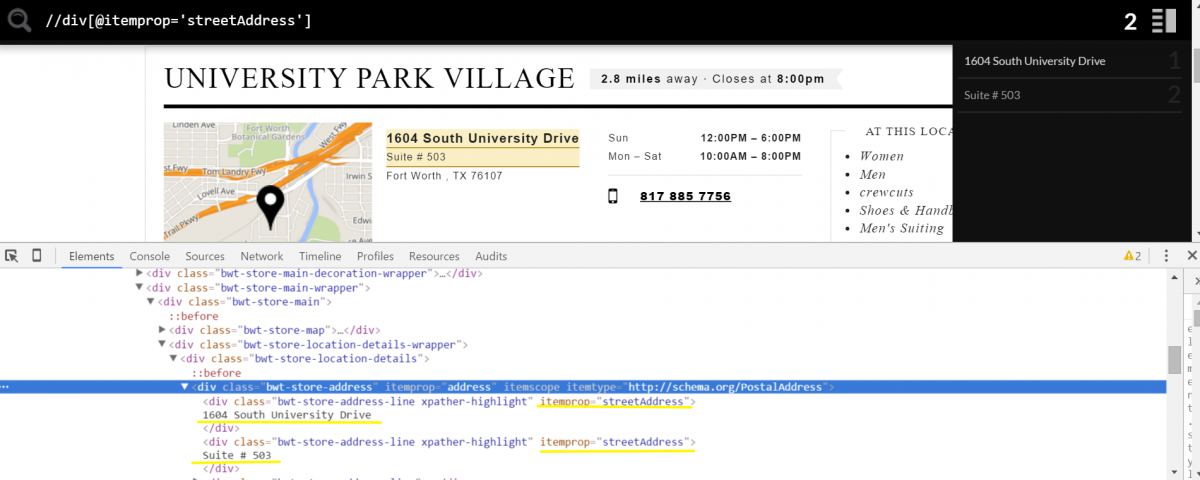
Location Data (PostalAddress)
- For Street Address, use the expression: //span[@itemprop=’streetAddress’]
- If the address has 2 lines like in the example below, you’ll also have to use the expression: //span[@itemprop=’streetAddress’][2] to extract the second occurrence.
- For City, use the expression: //span[@itemprop=’addressLocality’]
- For State, use the expression: //span[@itemprop=’addressRegion’]
Ratings & Reviews (AggregateRating)
- For star rating, use the expression: //span[@itemprop=’ratingValue’]
- For review count, use the exprssion: //span[@itemprop=’reviewCount’]
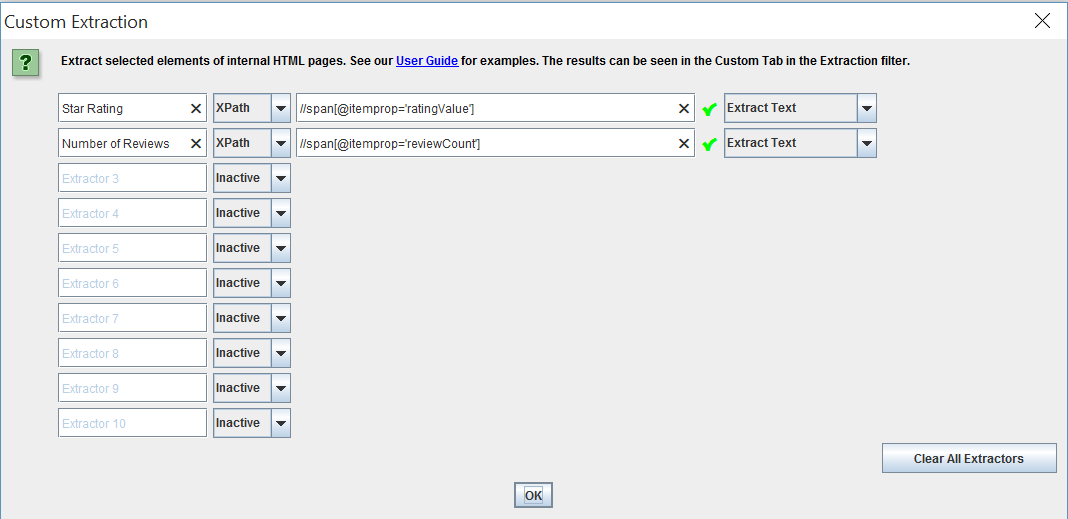
In this example, I extracted star ratings and review from an iTunes page for their top health and fitness apps and then sorted them by highest star rating. You can see the extracted data below.

Finding Schema Types
So what if you are unsure if the website in question is using Schema? You can search by Schema types by using the expression: //*[@itemtype=’http://schema.org/insert type here‘]/@itemtype.
Common types include:
- http://schema.org/Organization
- http://schema.org/Place
- http://schema.org/Product
- http://schema.org/Offer
OR you can set up the expressions like so:
- //*[@itemtype])[1]/@itemtype
- //*[@itemtype])[2]/@itemtype
- //*[@itemtype])[3]/@itemtype
- //*[@itemtype])[4]/@itemtype
Xpath for Extracting HREFlang Tags
There are two approaches you can take for scraping hreflang tags; you can scrape any instance of the tag or you can scrape by language.
To scrape by instance (which is helpful if you have no idea if the site contains hreflang tags or if you don’t know which countries are being used), you would use the expression: //link[@rel=’alternate’][1*]/@hreflang
*Enter a number from 1-10 (since Screaming Frog only has 10 fields you can use when extracting data). The number represents the instance in which that path occurs. So in the example below, the expression //link[@rel=’alternate’][4]/@hreflang would return “en-ca“.
<link rel=”alternate” href=”http://www.example.com/us” hreflang=”en-us” />
<link rel=”alternate” href=”http://www.example.com/ie/” hreflang=”en-ie” />
<link rel=”alternate” href=”http://www.example.com/ca/” hreflang=”en-ca” />
<link rel=”alternate” href=”http://www.example.com/au/” hreflang=”en-au” />

The only issue with this method is that results may not be returned in the same order and it may be difficult to discern which pages are missing hreflang tags with certain country and language codes (as seen in the example below). Ideally, each language and country code would have its own dedicated column.
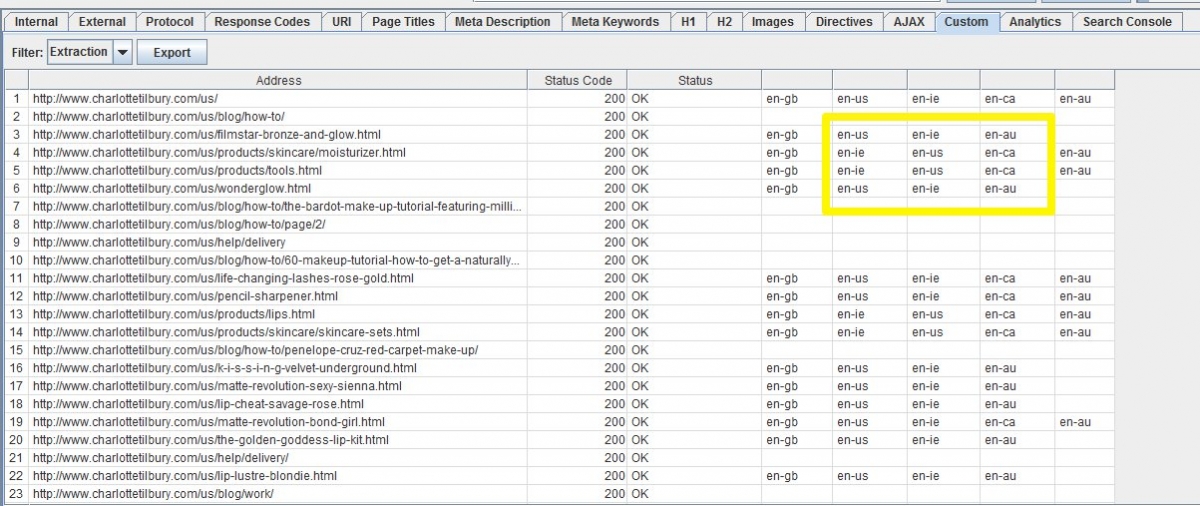
If you already know which countries you are checking for, you can use the expression:
//link[@hreflang=’insert language/country‘]/@hreflang

As you can see below, the results of the scrape are much cleaner and it is easier to see which pages are missing tags and which pages are not available in a particular country/language.

There’s also a Chrome extension you can use called Xpather (available for both Chrome and Firefox). Xpather features a search box at the top if your browser that allows you to input an xpath expression. By doing so, you can check to make sure you are using the correct syntax and see which results are returned using the given expression.

A big limitation with Screaming Frog that prevents it from being a full-fledged data mining tool is that you are limited to 10 fields to input your xpath expressions and it only allows for one result per data cell. For instance, if you had an e-commerce page with 30 different products and you wanted to scrape the prices for each product, you would only be able to extract the first 10 prices. If that’s your goal, you can try a Chrome extension called Scraper. Scraper allows you to quickly extract data from a web page into a spreadsheet.

Related Product:



